Kafka - Consumers
Alasta 28 Janvier 2025 kafka kafka opensource
Description : Description des consumers dans Kafka.
Kafka Producers
- Les Consumers lisent les données d’un Topic (identifié par son nom) : pull model
- Les Consumers connaissent automatiquement sur quel broker se connecter
- Les consumers savent gérer automatiquement la perte d’un broker
- Les données sont lues dans l’ordre du plus petit au plus grand offser pour chaque partition
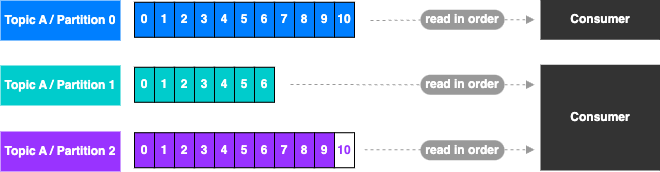
Deserializer
- Le Deserializer permet de transformer les Bytes en objet/data
- C’est utiliser sur les Value & Key des messages
- Les Deserializer communs:
- String (incl. JSON)
- Int, Float
- Avro
- Protobuf
- Le type de Serializer/Deserializer ne peut pas changer durant le cycle de vie (créer un nouveau topic à la place)
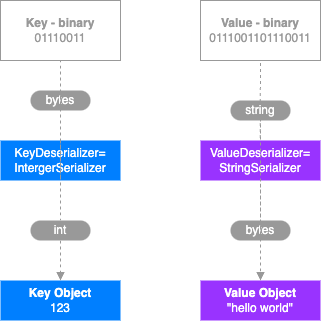
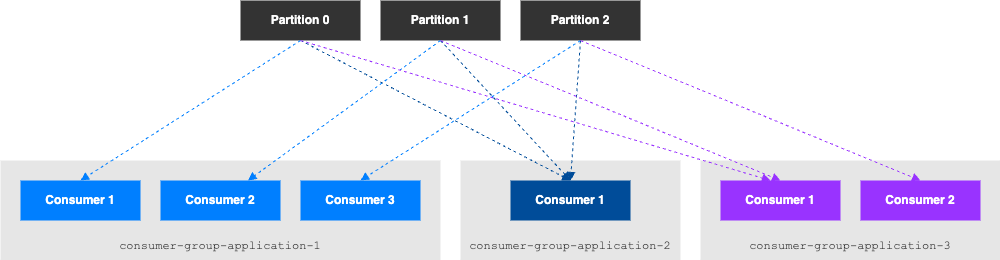
Consumer Groups
- Tous les Consumers dans une application lisent les données en tant que Consumer Groups
- Chaque Consumer dans un groupe lit depuis une/des partitions spécifiques
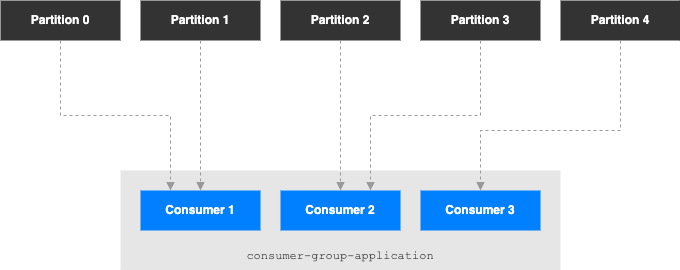
Qu’est qu’il se passe s’il y a beaucoup de consumer ?
- Si il y a plus de consumers que de partitions, il y aura des consumers inactifs.
Multiple Consumers sur un topic
- Kafka accepte d’avoir plusieurs consumer-group sur un même topic
Offsets
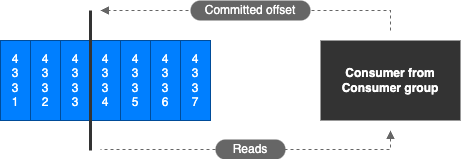
- Kafka stoque les offsets de chaque consumer-group qui ont été lus
- Les offsets commités sont stoqués dans un topic nommé __consumer_offsets
- Quand un consumer dans un groupe a traité des doonées de Kafka, il doit commiter périodiquement les offsets (c’est le Kafka broker écrit dans le topic __consumer_offsets)
- Si un consommateur meurt, il sera en mesure de relire à partir de l’endroit où il s’est arrêté grâce à l’offset qu’il a commité
Delivery semantics pour les consumers
- Par défaut, les consumers Java vont automatiquement commiter les offsets (at least once)
- Il y a 3 Delivery semantics que l’on peut choisir en commitant manuellement
- At least once (principalement utilisé)
- Les offsets sont commités après que le message soit processé
- S’il y a un problème dans le processing du message, il redevient disponible en lecture
- Il peut en résulter une duplication de processing de message, il faut s’assurer que le process est idempotent
- At most once
- Les offsets sont commités aussitôt que les messages sont reçus
- S’il y a un problème dans le processus, des messages peuvent être perdu (ils ne pourront plus être lus)
- Exactly once
- Pour Kafka: Kafka workflows, utiliser the transactional API (facile avec Kafka Streams API)
- Pour Kafka: External systm workflows: utiliser un consumer idempotent.
- At least once (principalement utilisé)