ES - Quelques bases
Alasta 29 Avril 2016 bigdata shell cli BigData elasticsearch
Description : Voici quelques bases pour comprendre Elasticsearch.
Description :
Nous allons voir quelques bases sur Elasticsearch qui est un moteur de recherche puissant.
Ce moteur se base sur Lucene pour l’indexation et la recherche.
Terminologie :
- index : collection de documents, est l’équivalent d’une base de données dans un SGBD.
- document : donnée unitaire contenue dans un index, équivalent à une ligne dans un SGBD. Un document peut avoir plusieurs champs.
- type : classe de document similaire, pourrait être l’équivalent de la table en SGBD. Il peut y eb avoir plusieurs par index.
- mapping : définition explicite ou implicite des caractèristiques des champs à indexer, équivalent au schéma en SGBD.
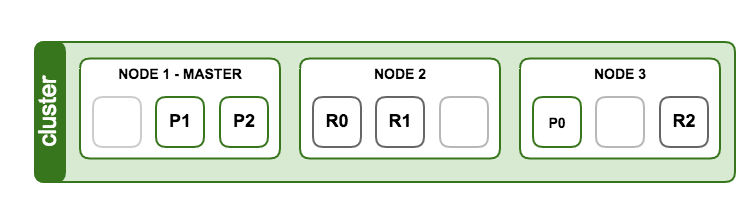
- node : instance (processus) Elasticsearch.
- cluster : ensemble de node Elasticsearch sur lesquels sont répartis des index.
- id : identifiant d’un document.
- primary shard : chaque document est stocké dans un primary shard. Quand un document est indéxé, il est en premier dans le primary shard puis tous les replicas.
- replica shard : chaque primary shard a 0 ou plusieurs replicas, un replica est une copie du primary shard
- field : c’est une association de clé/valeur, un document contient une liste de fields.
Note :
Les documents sont stockés au format JSON et ont un index, un type et un id en plus des données.
Plusieurs nodes peuvent être lancés sur un même serveu, mais il est conseillé d’en avoir qu’un par serveur.
Les replicas shard ont 2 fonctionnalités :
- augmenter le failover : un replica shard peut être promu primary shard en cas d’incident.
- augmenter les performances : les requêtes get et search peuvent être traitées sur les primary et replicas shard.
Indexation :
|
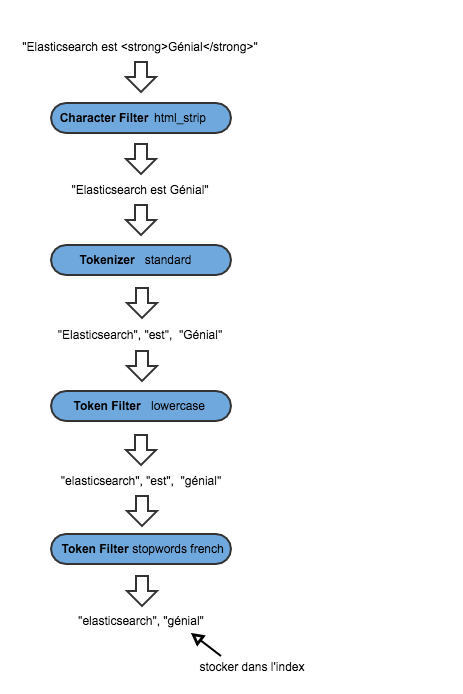
Character Filters Traitement des chaînes de caractères avant de les passer au tokenizer. Par exemple supprimer les tags HTML.
Tokenizer
Token Filters |
|
</tr>
</table>
#### Exemple avec le *character filter* html_strip et *tokenizer* standard